




강재우 교수팀, X-ray 영상 시각정보와 검사소견 언어정보 동시 학습 시각언어 인공지능 모델 개발...23만 장의 흉부 X-ray 영상과 12만 건의 검사 결과를 학습한 AI 모델 'CheXOFA'

고려대학교(총장 김동원) 컴퓨터학과 강재우 교수 연구팀이 흉부 X-ray 영상에 대한 검사결과를 요약하는 인공지능 시스템 국제경진대회 RadSum에서 스탠포드대학교 (Stanford University), 지멘스, 유니버시티칼리지 런던(University College London), 텍사스대학 샌안토니오(The University of Texas at San Antonio) 등을 제치고 1위에 올랐다.
고려대학교 팀은 김강우, 김하정, 김찬휘, 성무진, 김현재 등 대학원생과 지도교수인 강재우 교수로 구성되었으며, 고려대 연구팀을 중심으로 마이크로소프트 연구소 아시아 (Microsoft Research Asia), 아이젠사이언스, KAIST, 베이징 항공항천대학(Beihang University)의 연구원들이 힘을 보태 다국적팀을 구성해 참가했다.
RadSum 대회는 스탠포드 의료 이미지 인공지능 센터(AIMI, Center for Artificial Intelligence in Medicine & Imaging)에서 주관하는 대회로, 강재우 교수 연구팀이 참여한 MIMIC-CXR 챌린지는 흉부 X-ray 영상과 검사소견을 기반으로 진단을 추론하는 과제를 수행했다.
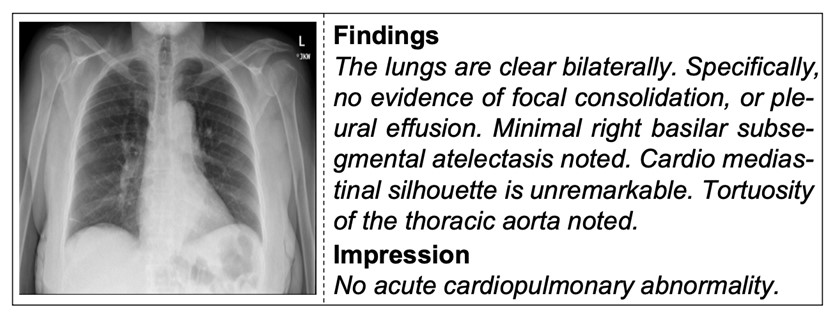
예를 들어, 아래 사진과 같은 흉부 X-ray 영상과 임상의가 작성한 검사소견(“Findings”)을 기반으로 최종 결론에 해당하는 추정진단 “Impression”을 생성해야 한다.
대부분의 참가팀들이 챗GPT의 기반 기술인 트랜스포머(Transformer) 구조의 언어모델을 사용해 텍스트 형태의 검사소견만을 입력으로 받아 진단을 생성한 반면, 강재우 교수팀은 X-ray 영상의 시각정보와 검사소견의 언어정보를 동시에 활용하는 시각언어모델 'CheXOFA'를 개발해 대회에 참가했다.
CheXOFA(논문, RadSum23의 KU-DMIS-MSRA: 방사선 보고서 요약을 위한 사전 훈련된 시각 언어 모델/KU-DMIS-MSRA at RadSum23: Pre-trained Vision-Language Model for Radiology Report Summarization-다운) 역시 트랜스포머에 기반한 모델이나 텍스트 뿐만 아니라 이미지, 영상 등도 같이 입력 및 출력(생성) 할 수 있도록 확장된 멀티모달 인공지능 모델이다.
CheXOFA는 약 23만 장의 흉부 X-ray 영상과 임상의들이 작성한 약 12만 건의 검사결과를 사전학습하였으며, 입력된 영상과 소견으로부터 진단을 생성하는 본 대회에서 활용되었던 기능 이외에도 X-ray 영상만을 입력으로 받아 영상에 대한 검사소견을 생성하는 등 다양한 태스크를 수행할 수 있다.
RadSum 대회는 2023년 1월에 학습 데이터를 공개하였고 이후 3개월간 참가팀들이 각자의 방식으로 인공지능 모델을 개발해 학습시켰다. 4월 6일 테스트 데이터가 공개된 이후 4월 28일까지 리더보드가 운영되며 각 참가팀들의 인공지능 모델의 성능 경합이 이루어졌다.
한편, 대회 최종 순위와 우승팀은 지난 9일부터 14일까지 캐나다 토론토에서 개최된 제61회 전산언어학회(ACL 2023, Association for Computational Linguistics)의 'BioNLP 2023' 워크샵에서 지난 13일 발표됐다.